PORTFOLIO | Dongying LIU
A Study of Pitch Range Estimation Based on Neural Network
Partner: Tiantian Li, Jingyi Wang, Jiaxing Jiang
My role: team leader, programmer
May 2018 to July 2019
Research Background
What is pitch range:
-
Pitch range is the highest and lowest pitch a person can reach when talking, which is decided physiologically and varies from person to person.
Four tones in Mandarin and their relationship with pitch range:
-
There are four unique tones in Mandarin Chinese.
-
The four tones have their own range of change according to the personal pitch range.

Motivation & Idea
-
As a student of Beijing Language and Culture University full of foreign friends learning Chinese, we found that there is a common problem when teaching Chinese as a foreign language, which is the weird pronunciation of the four unique tones in Chinese.
-
There are plenty of Apps that help foreign friends in learning Chinese. However, due to techniques, we can’t offer users a correct pronunciation according to their actual pitch range. For example, when a high pitch girl pronounces in the wrong tone, we can only offer her the correct example read by a man with a bass voice, which is not helpful when they imitate and correct their pronunciation.

Traditional Method
About 4h acoustic signals
Manually computing
Complicated and time-consuming
Our Method
Only one Short-term acoustic signal about 300ms
Neural Network
Accurate and fast
Goal
-
Find out the neural network with the best performance on pitch range estimation.
-
Detailed system design.
-
Make a precise API for the best-performed model.
Technical Workflow

Step 1: Dataset preparing
Based on the AISHELL open source Mandarin Speech Corpus and the Mandarin Speech Corpus Recorded by Japanese Chinese Language Learners(made by BLCU Speech Acquisition and Intelligent Technology Lab), I used Praat to extract ceiling, floor, average and variance of every record, and used Kaldi on the Linux Server to extract the Fbank features. Then I used python to arrange them into the right form as the training and testing datasets.


The prepared dataset of one Speech
Step 2: DNN, RNN, LSTM building and optimizing
My main role is building and optimizing the DNN, RNN, LSTM with Keras base on Tensorflow.
-
Increase number of hidden layers and neurons
-
Use regularization to prevent overfitting
-
Try different activation functions
-
Modify learning rate
-
Add early stop
-
...
While using these ways to optimize DNN, RNN, LSTM separately, I used tensorboard to visualize the training process to find out the problem and increase the accuracy. I tried nearly 90 different combinations of hypermeters.





The Best Performed LSTM Model


The Best Performed LSTM Model
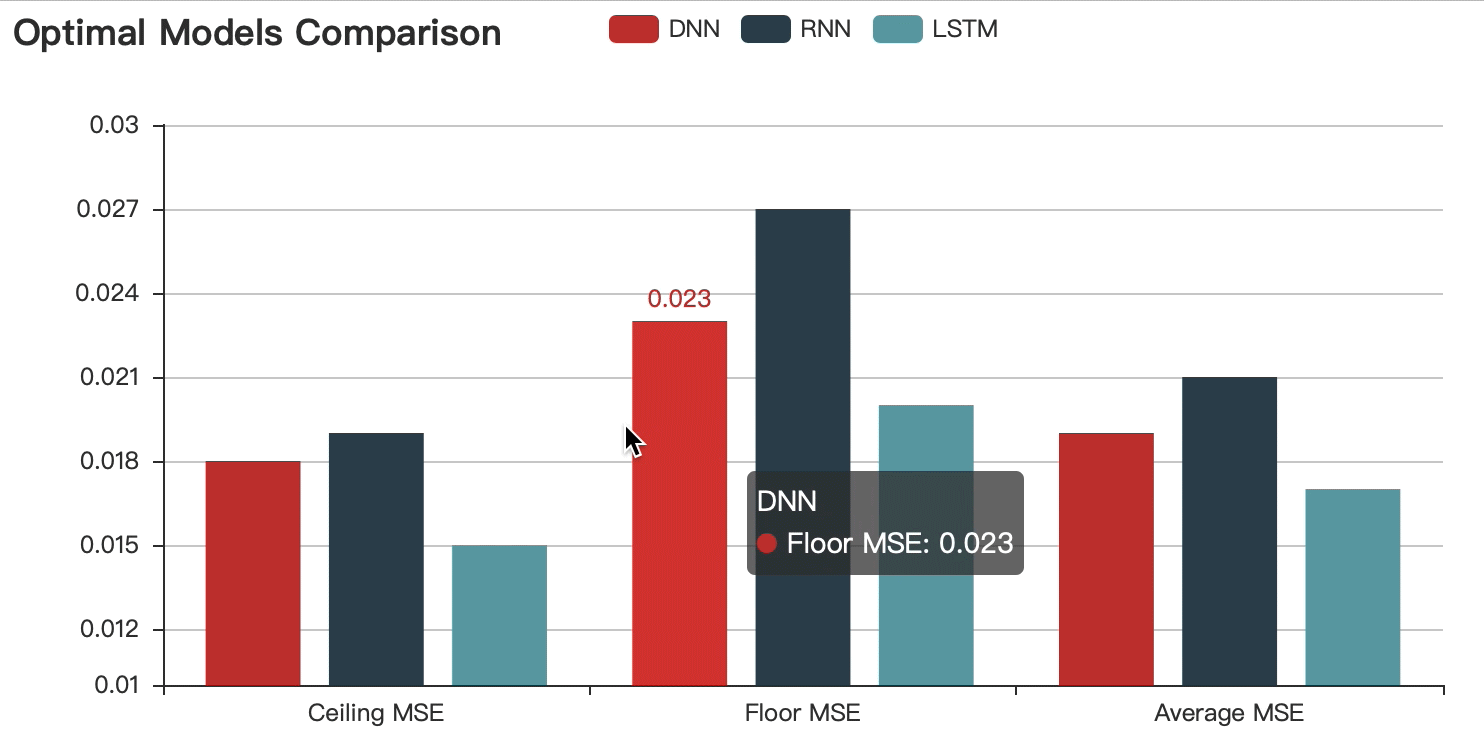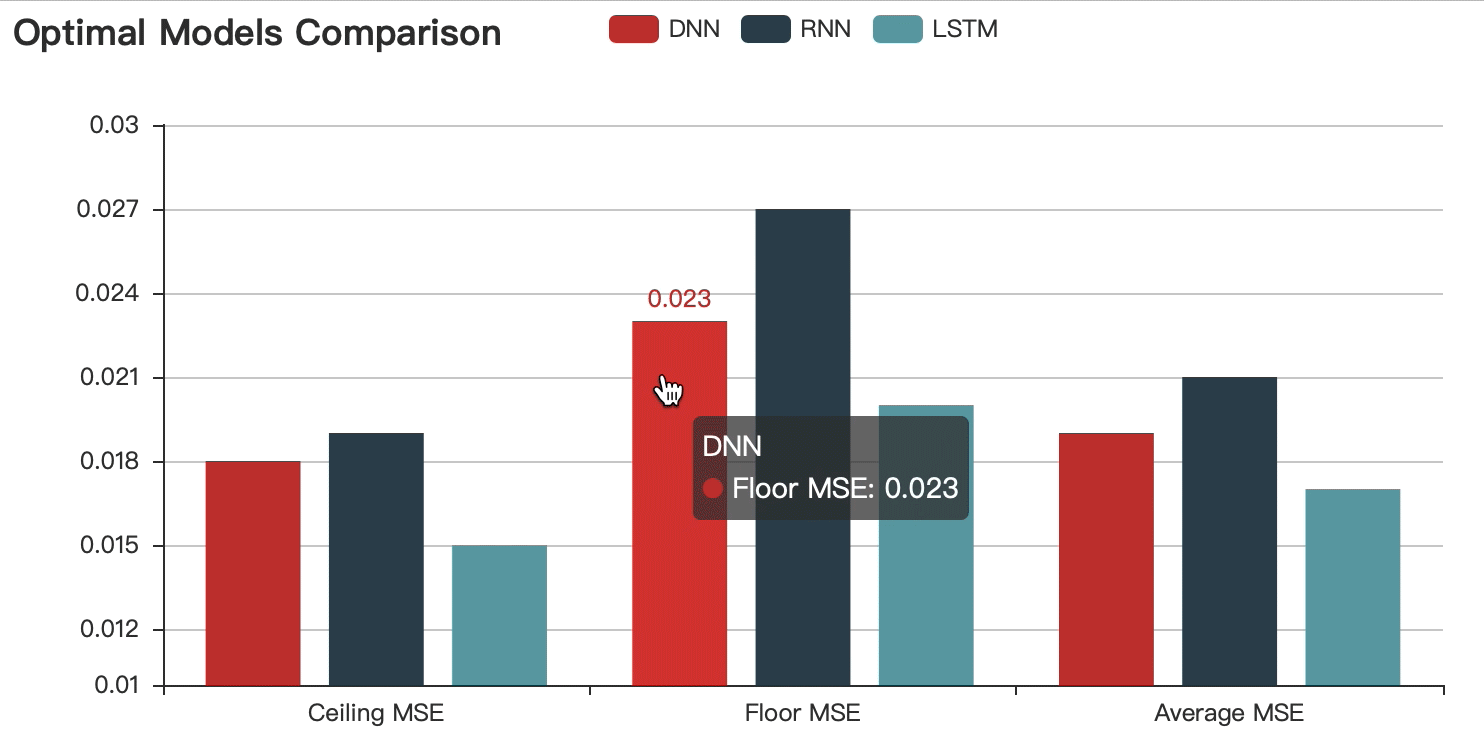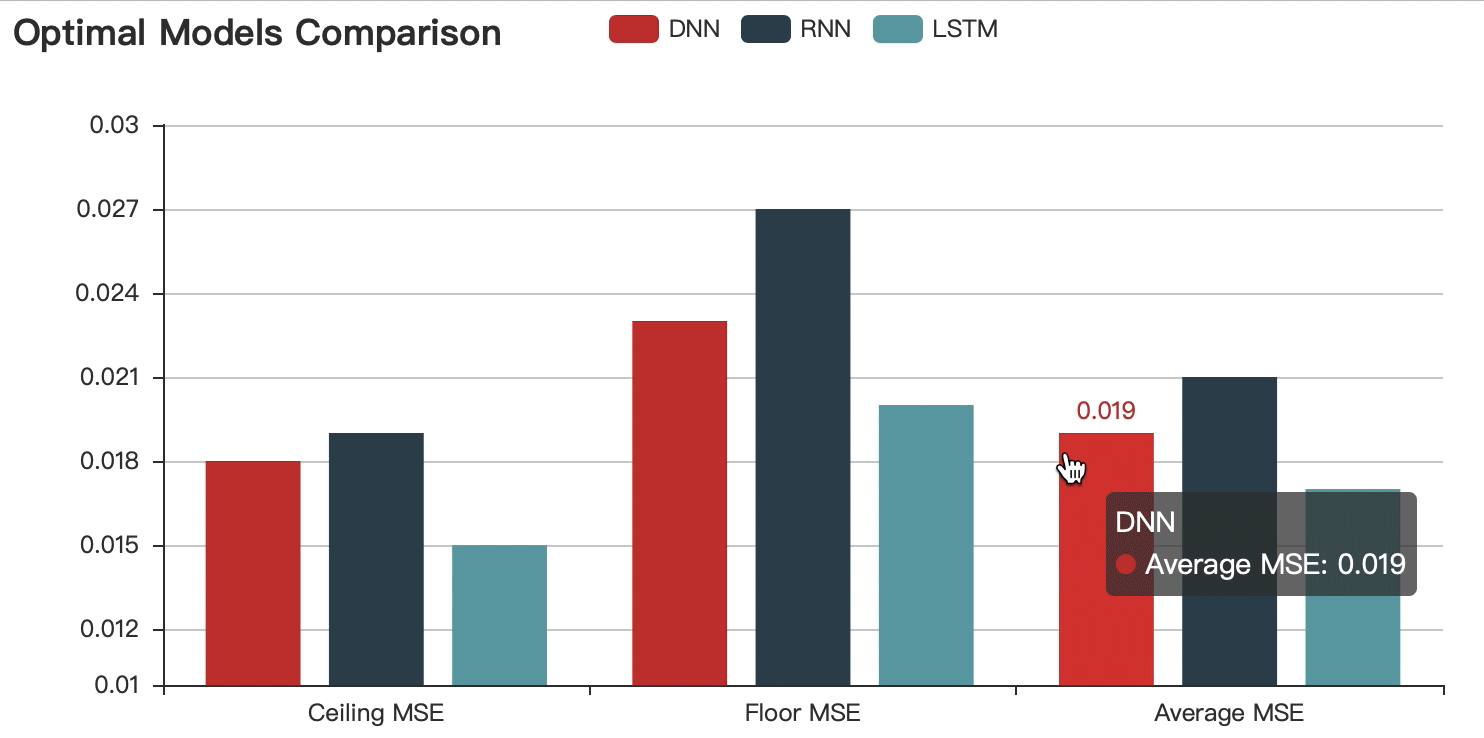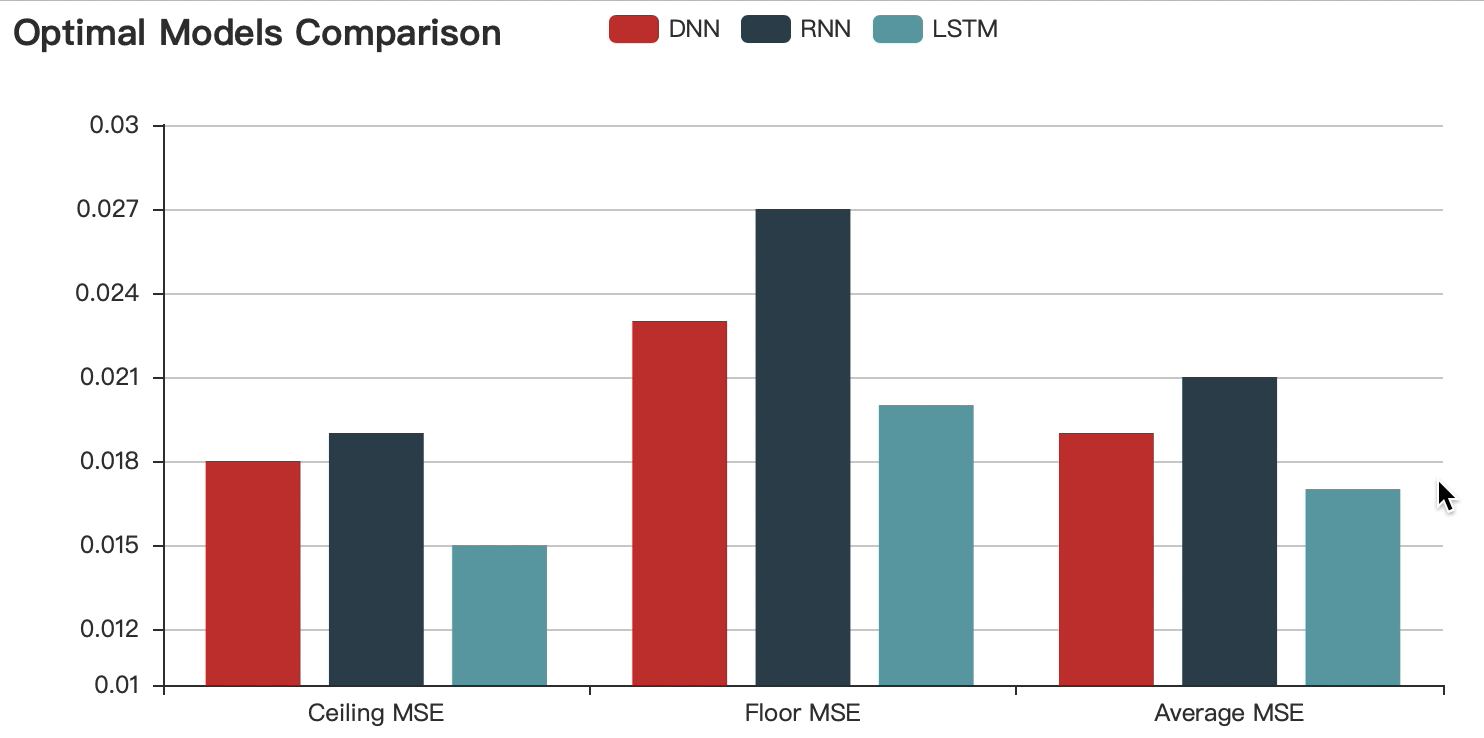
Optimal Models Comparison
-
After comparing and choosing the optimal model, I added the dataset to further optimize the chosen LSTM(2 hidden layers - 512 neurons - 0.8 dropout) . Eventually, The best performed model can reach 98% accuracy.
-
To proved that short time acoustic signals processed with deep neural network are capable of estimating the pitch range of a speaker. I fed the Fbank features involving 50ms, 100ms and 300ms into the LSTM.



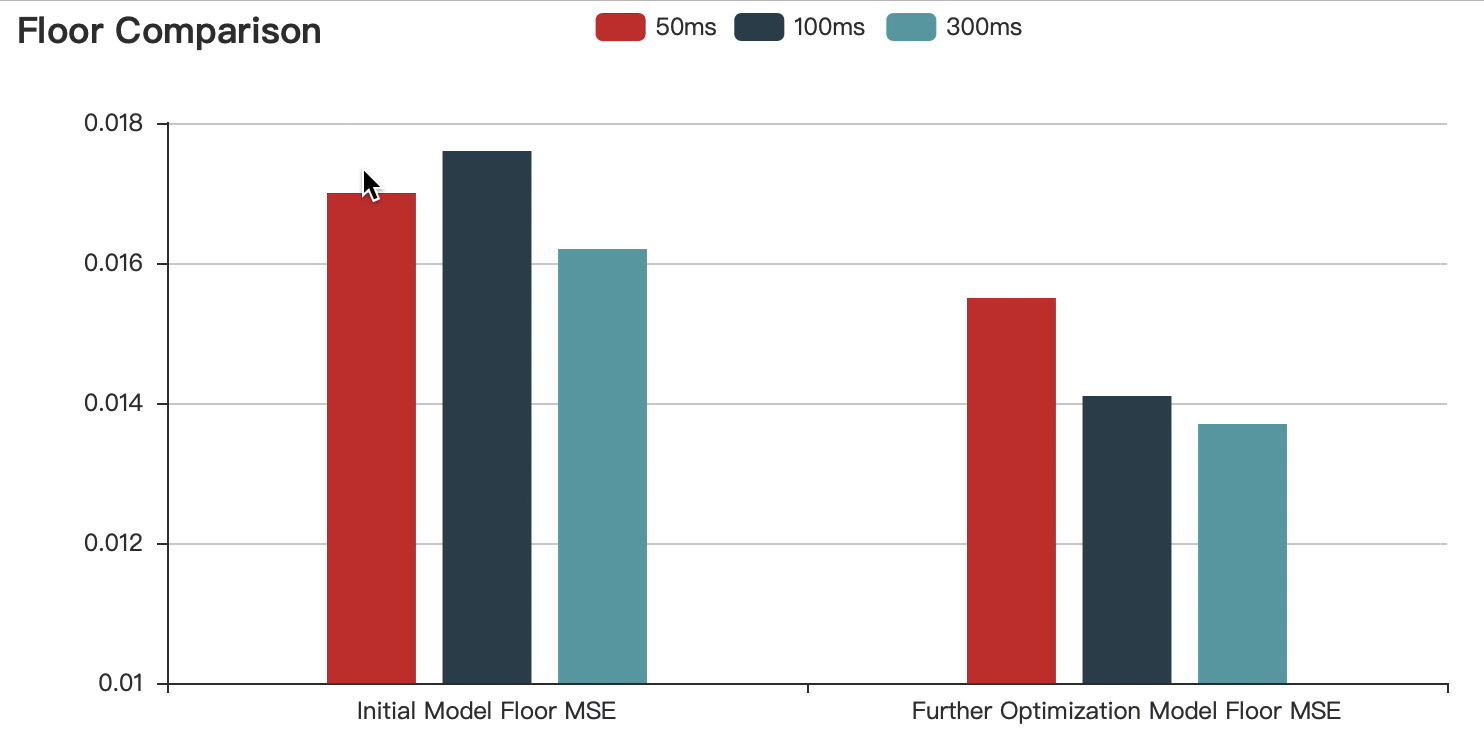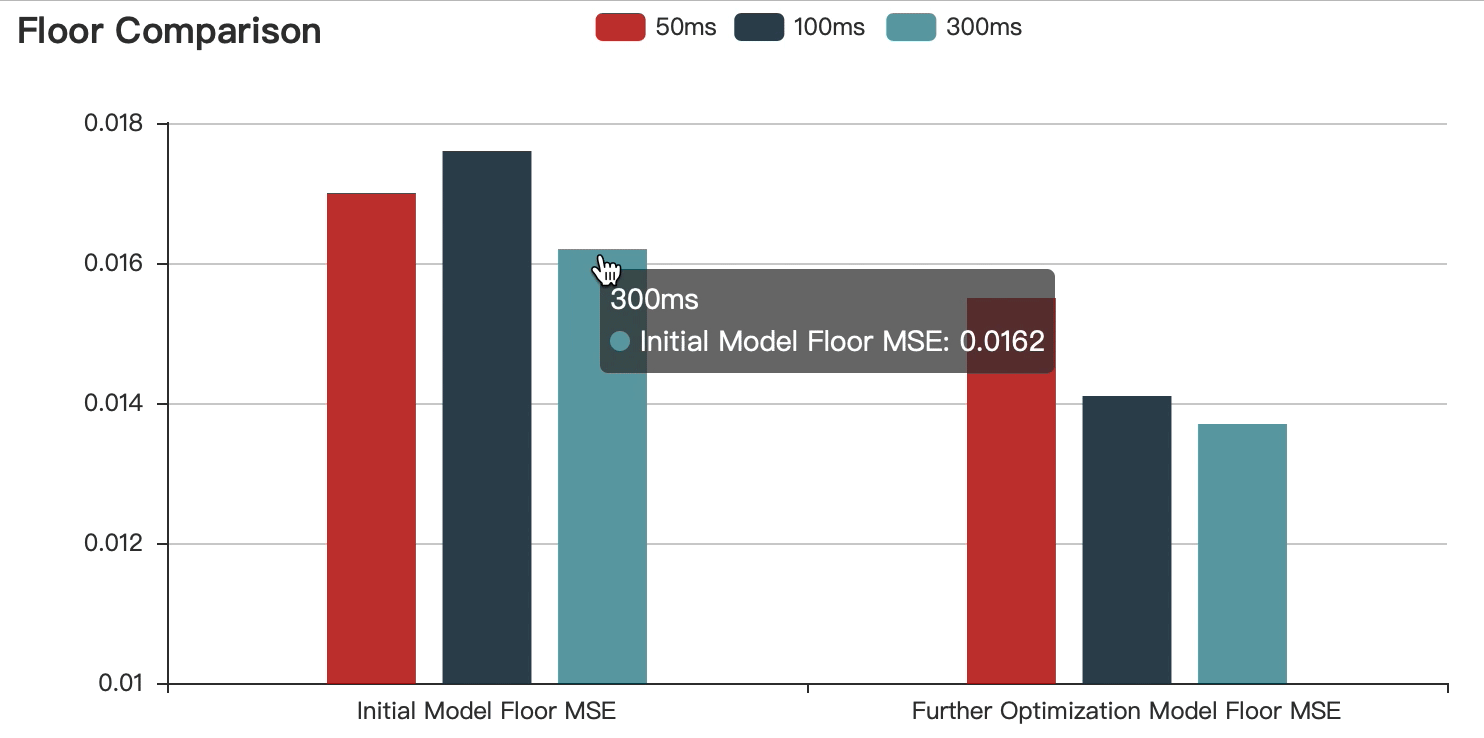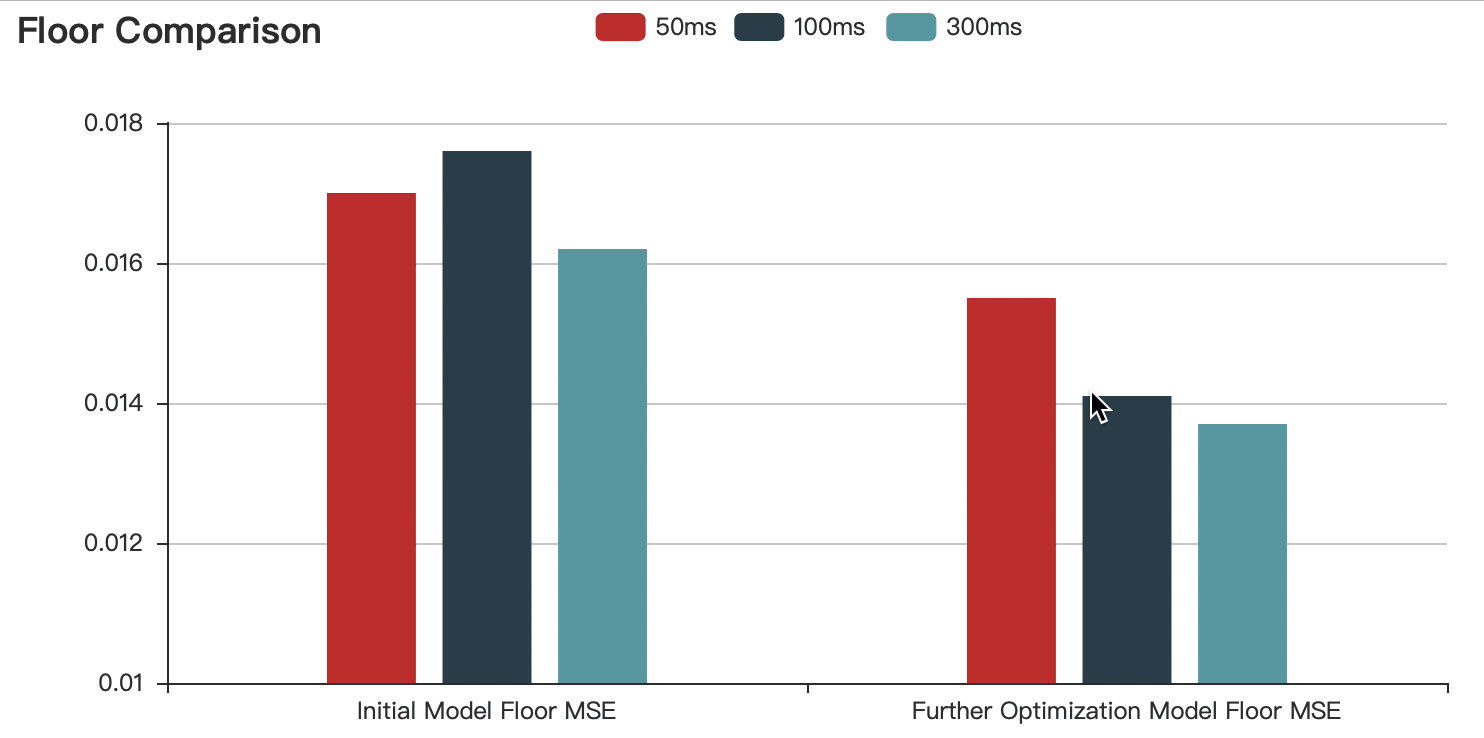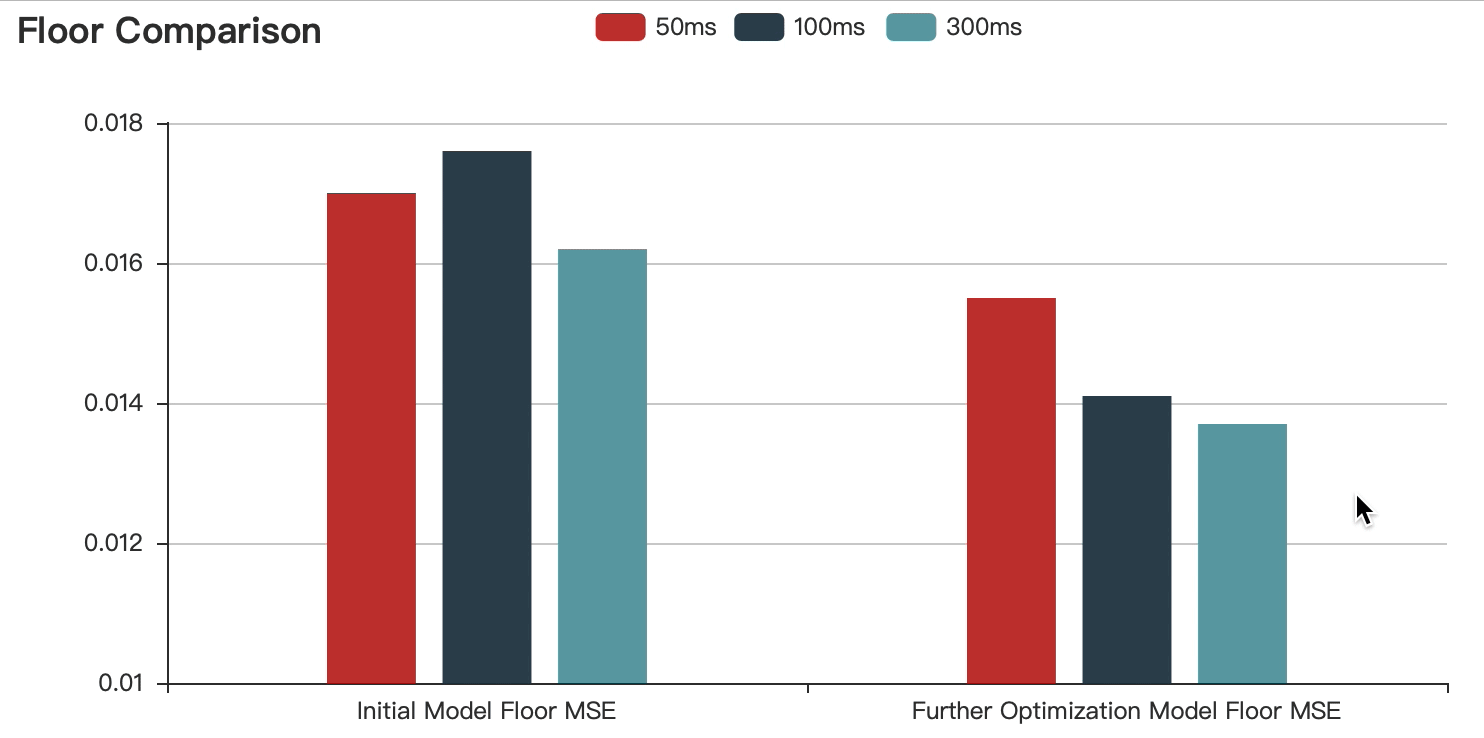
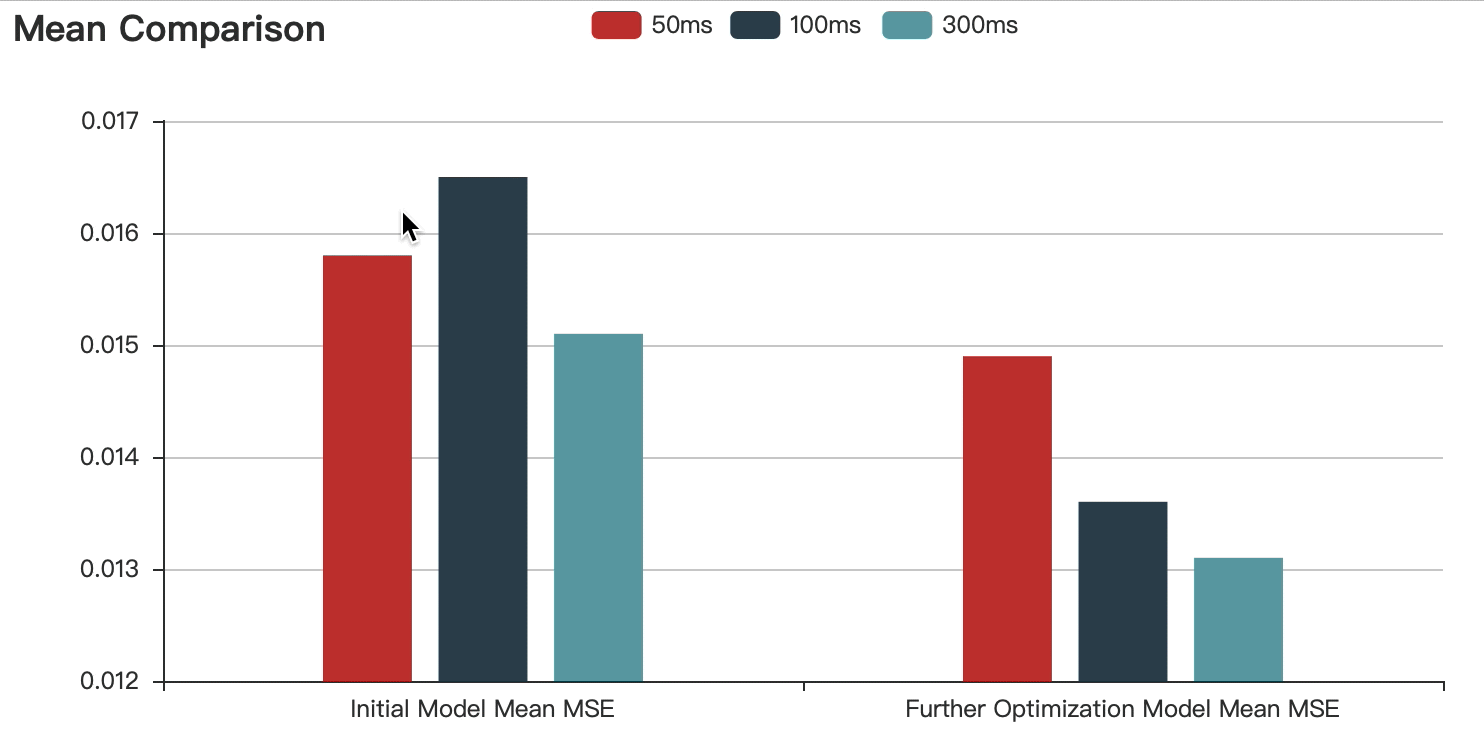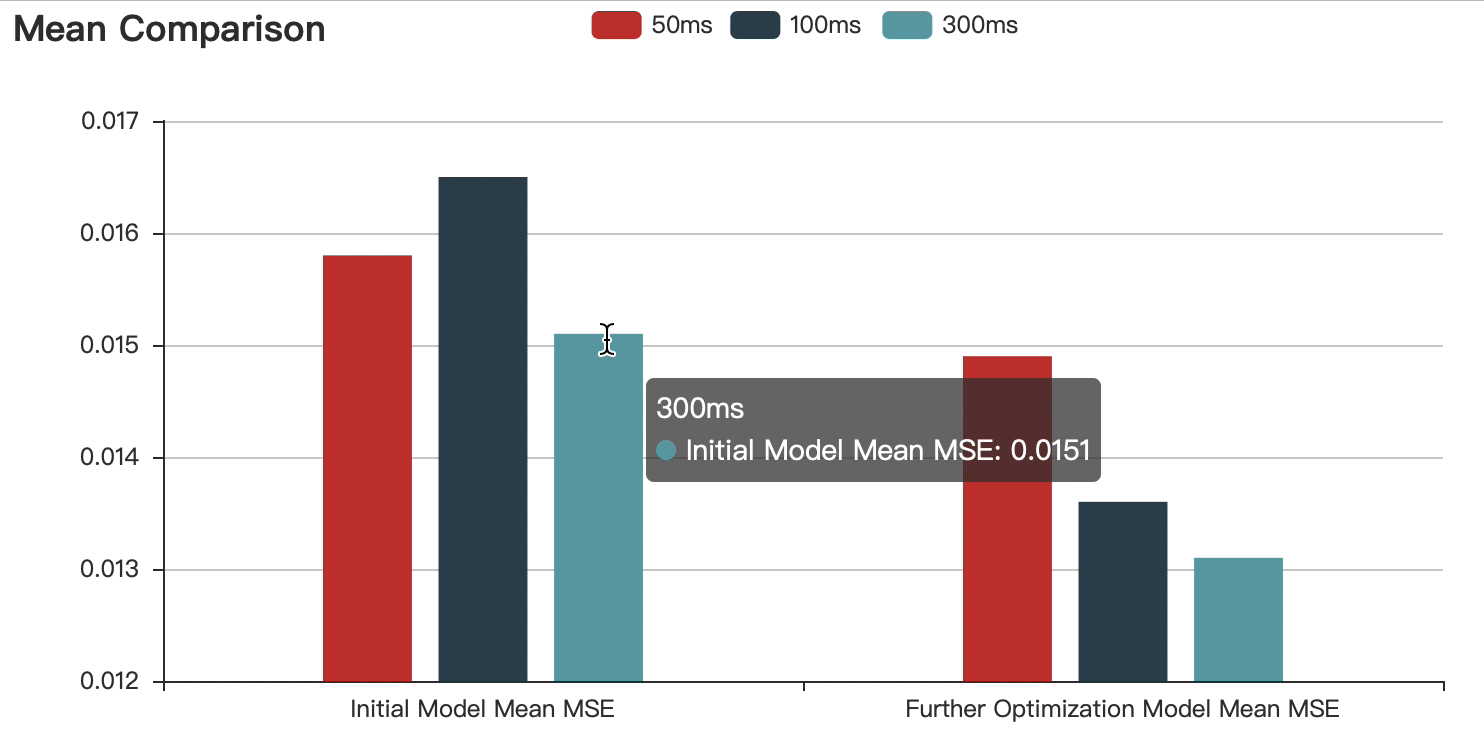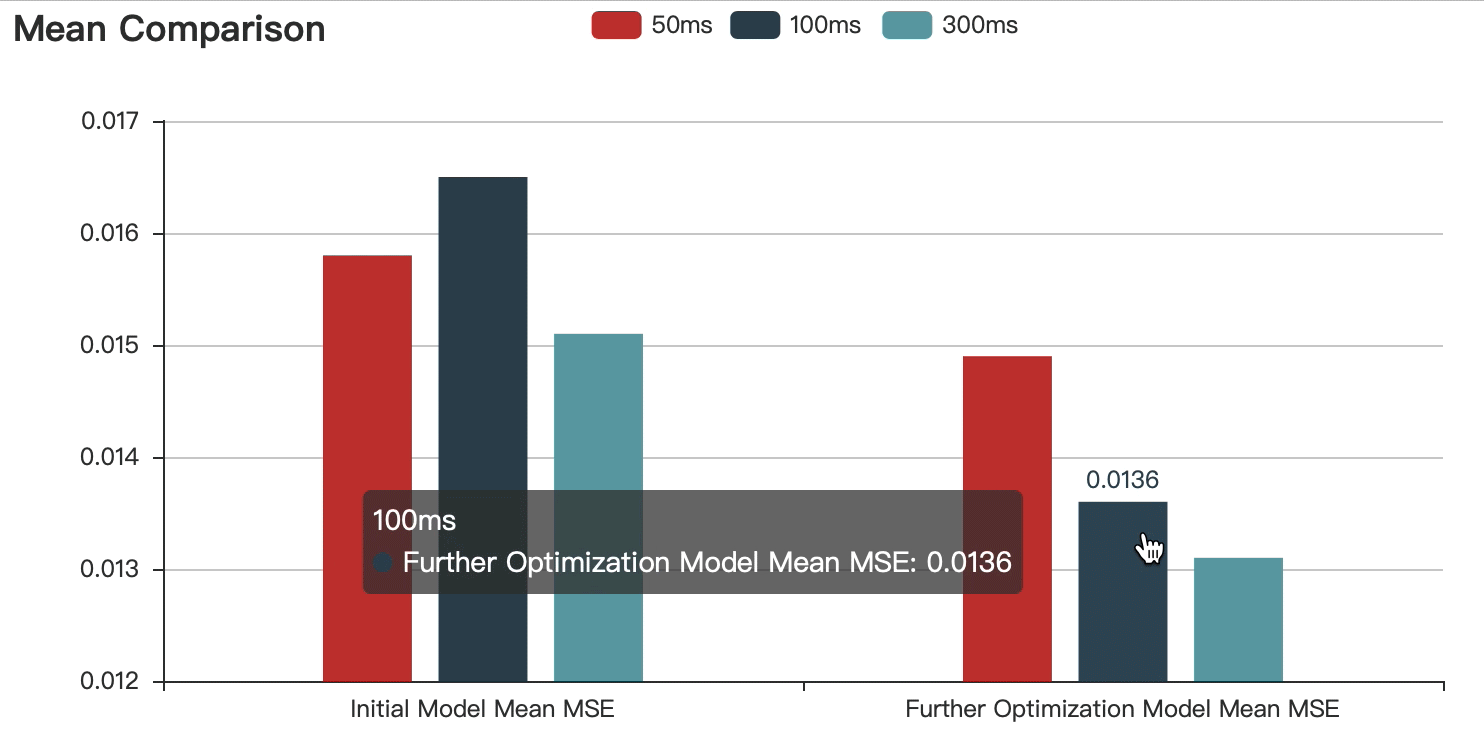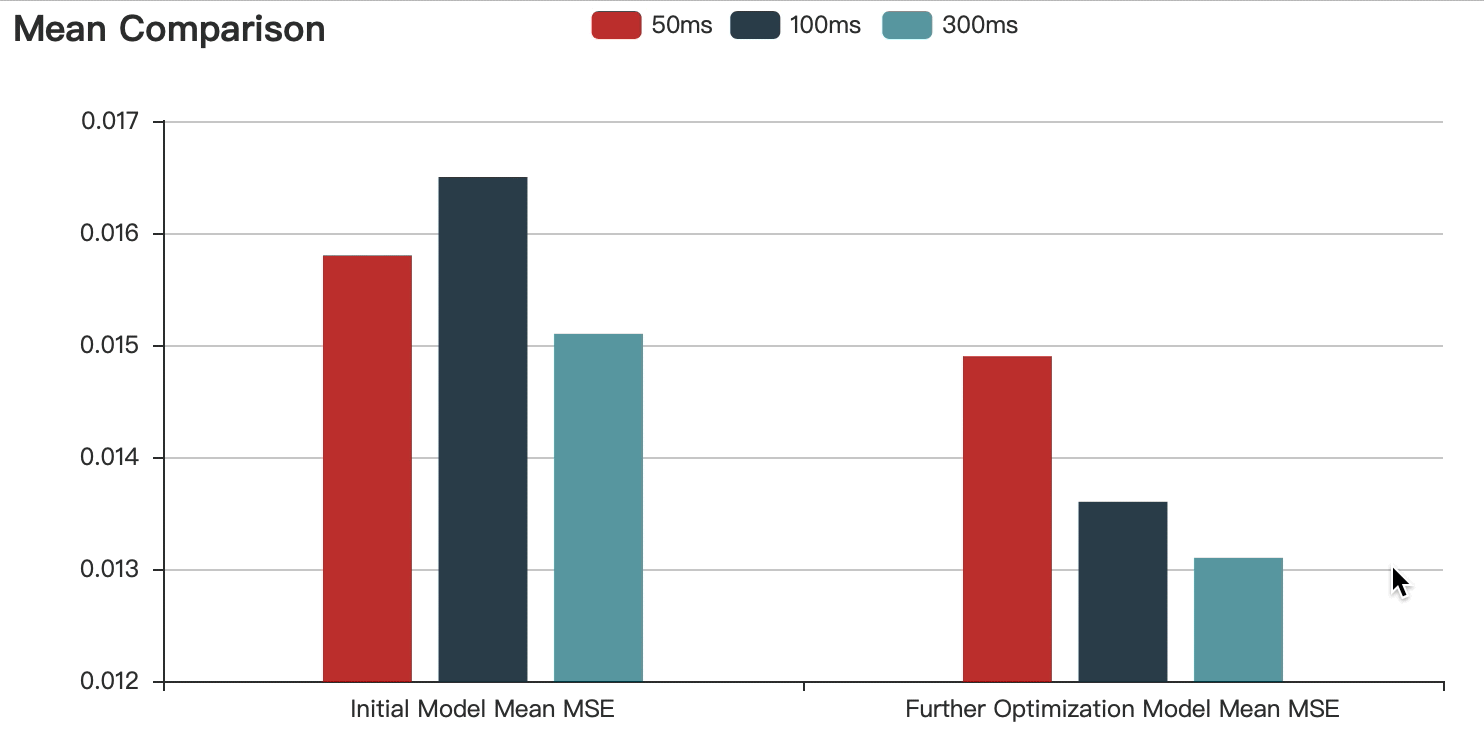
The graphs show that:
-
Compared with the initial model, the accuracy of the optimized model is improved.
-
With the increase of speech duration, the prediction error decreases continuously, but the difference is within the acceptable range.
In order to proved that the model can assist the teaching Chinese as a foreign language, we also fed the test dataset recorded by Japanese Chinese Learners(made by BLCU Speech Acquisition and Intelligent Technology Lab) . The results are shown in the following figure:
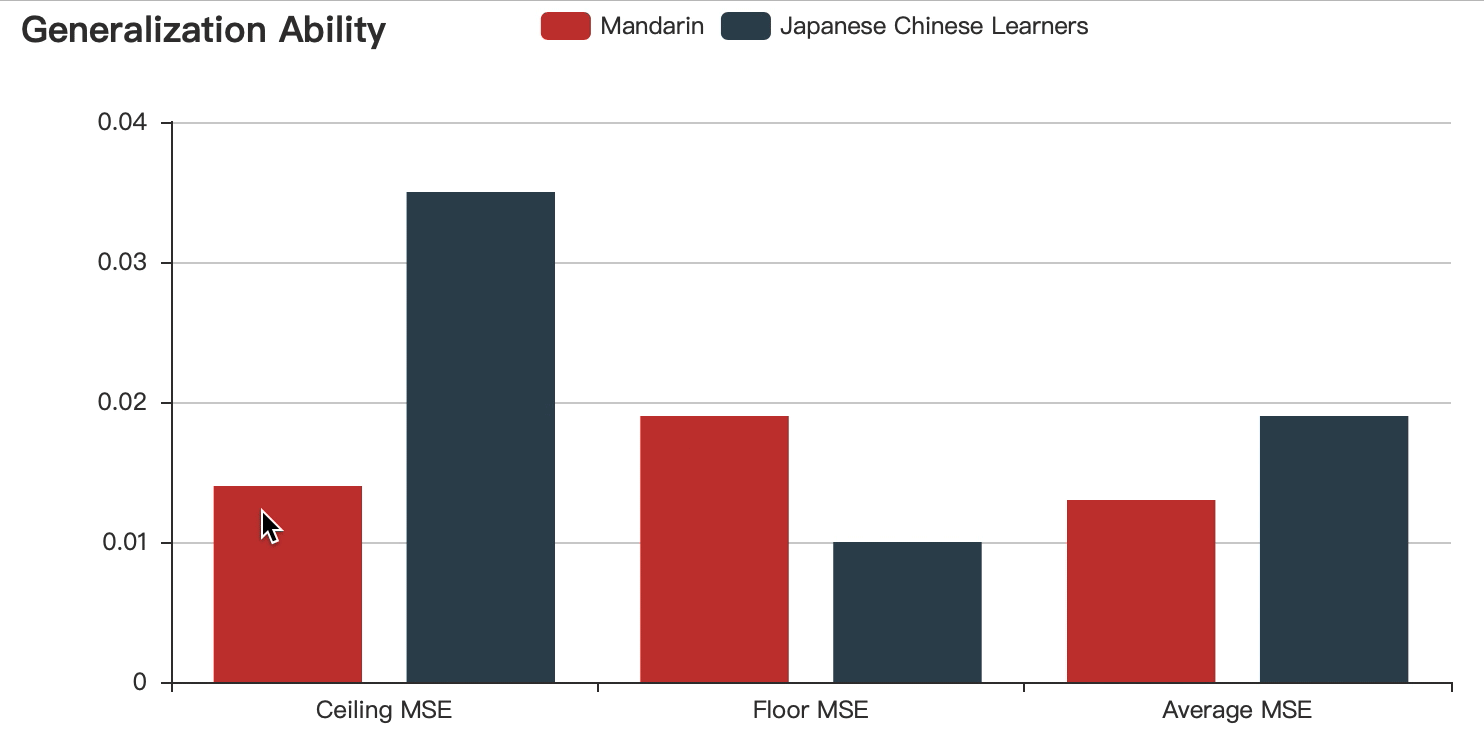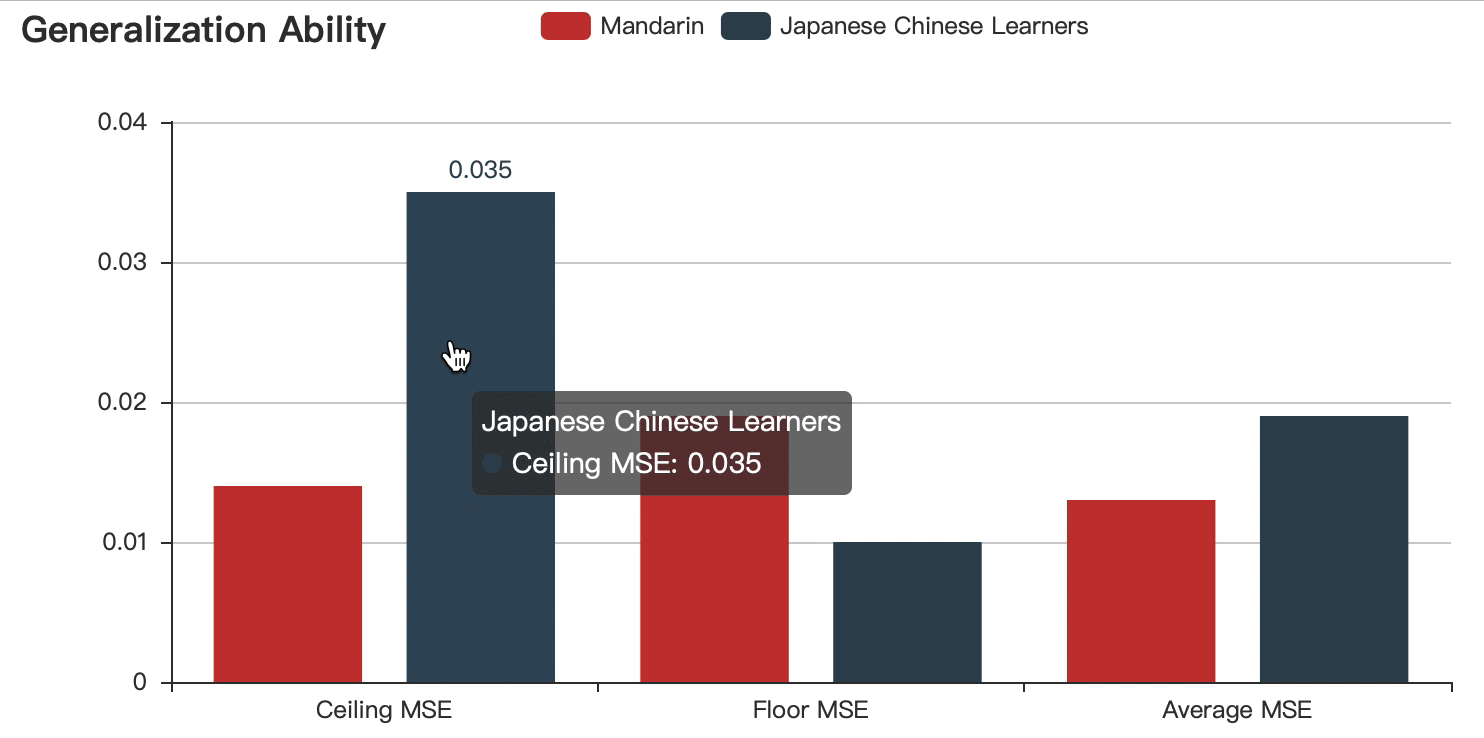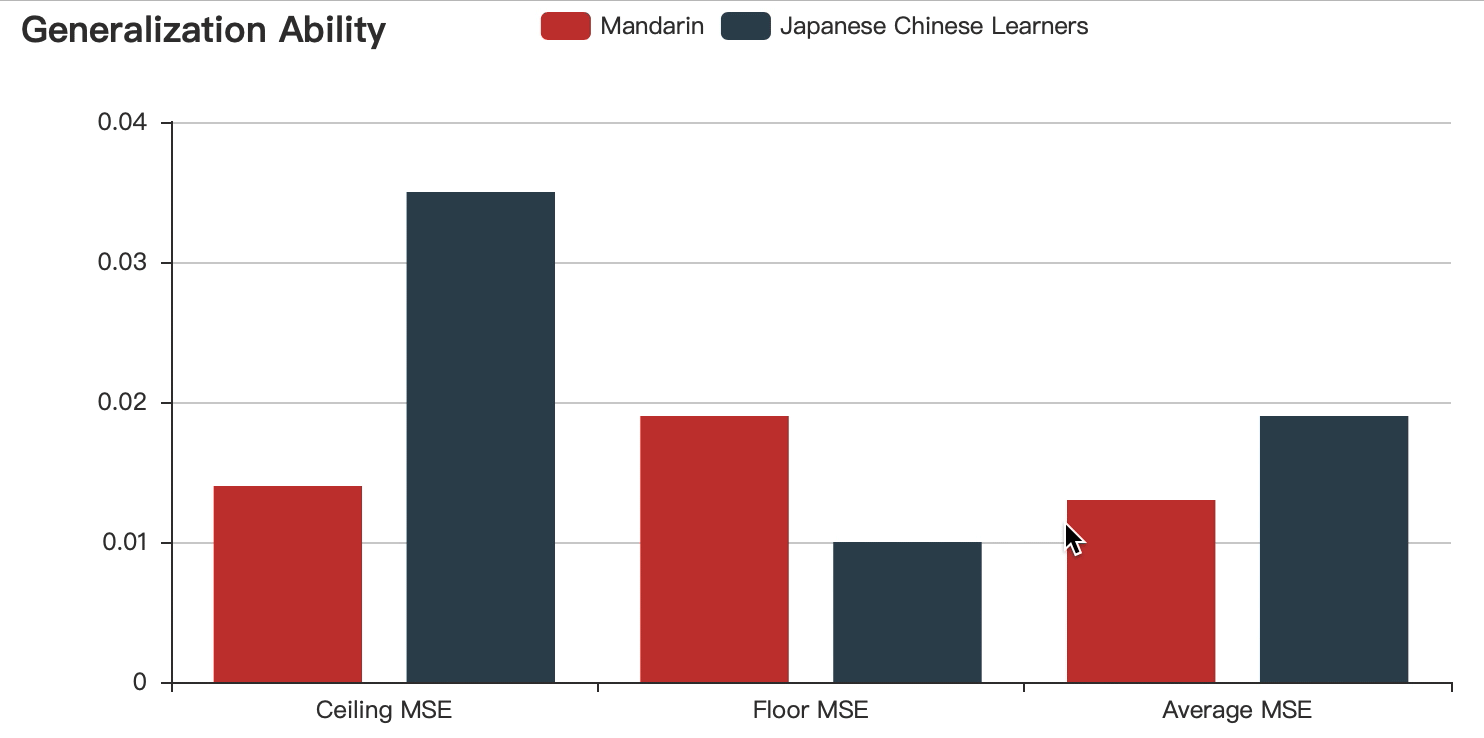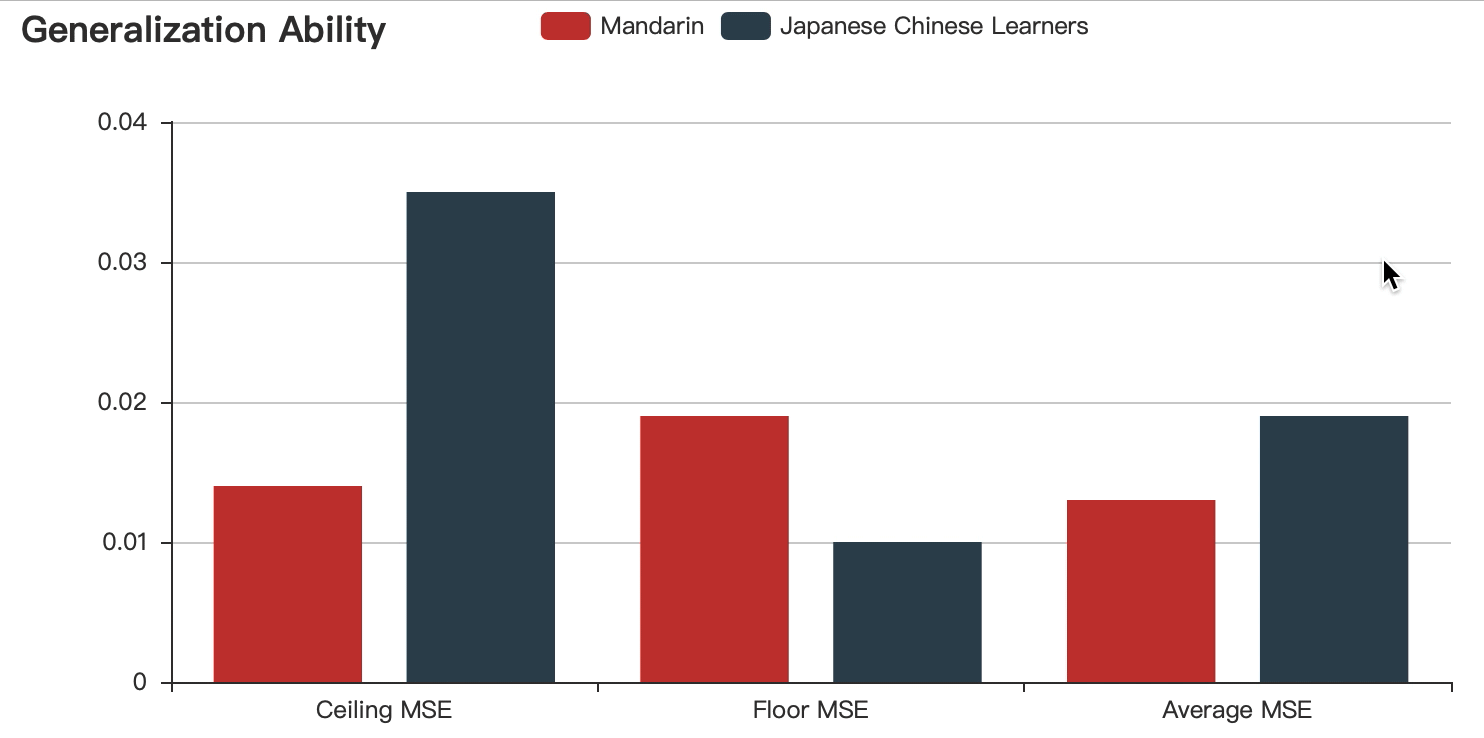
Step 3: API Making & Detailed System Design
Based on python, I made a precise API. It can load our optimal model and estimate the pitch range on one speech.
